
Recommender Systems for Patent Processing
The intellectual property economy, and, more narrowly, the patent economy, form an incredibly wide-reaching and important part of the economic activity of the United States, and of the broader world. The patent ecosystem involves a diverse collection of players and interests, as can be seen by following the lifecycle of a typical patent in Fig. 1. Inventors conceive of an idea, then patent agents and attorneys help them author and defend/refine a patent application, interact with patent examiners at the patent offices who review it, and check for novelty, prior art, and usefulness (or industrial applicability). Once the patent is issued, and even sometimes while it is still in the application phase, middlemen companies may buy and sell it. A company owning a patent may then request that other companies license its use. Standards organizations, such as 3GPP or IEEE, are also important participants in the lifecycle of many important patents, since often certain patents are required in order to implement standards, and hence license agreement structures, such as the FRAND (fair reasonable and non-discriminatory) agreement, are set up to coordinate their licensing for use. Finally, if a company decides that another company is likely infringing on its patent, it may bring a case, which the federal courts must then hear.
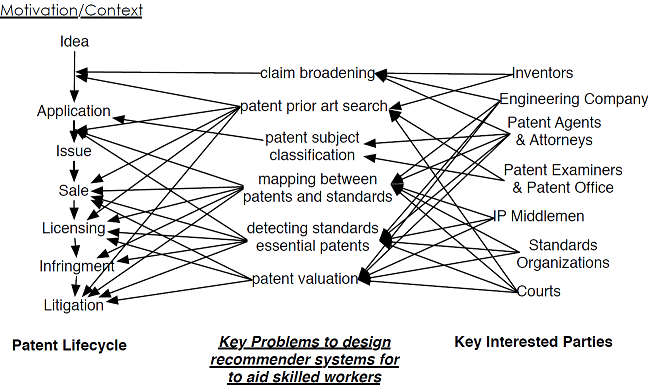
To achieve these goals, these participants perform multiple time-consuming and costly methods as depicted in Fig. 1. Inventers and patent agents must train and practice in the art of claim writing in order to write proper claims [1]. These claims need to cover multiple variations of an inventer’s idea but not be too broad to cover already created inventions. Prior art search, used when applying for a patent as well as in litigation, can require hundreds of man-hours to find just a handful of related documents from a pool of potentially millions of unrelated documents [2, 3, 4, 5]. Patent examiners need to understand the patent classification systems they use as well as the different categories in their field in order to determine the correct categories to assign a patent [5]. When companies come together to write standards, these companies need to determine which of their patents are related to the standards documentations. If a particular company did not suggest that particular addition to the standard, they will need to search their patent profile to see if any patents could be related to that addition[6, 7, 8, 9, 10]. Patent valuation requires analyzing trends in the technology to predict the value of a particular technology via reading and analyzing hundreds of documents about technology [11, 12, 13, 14, 15, 16].
Most of these tasks require determining a way of representing whole patents for comparison against other patents and even other non-patent documents. One method that preserves the grammatical structure of a patent is a dependency list [17, 18]. Dependencies list pair of words in a sentence and explain how they are related. Dependency relationships can be generated from parse trees - ordered, rooted trees that represent the syntactic structure of sentences.
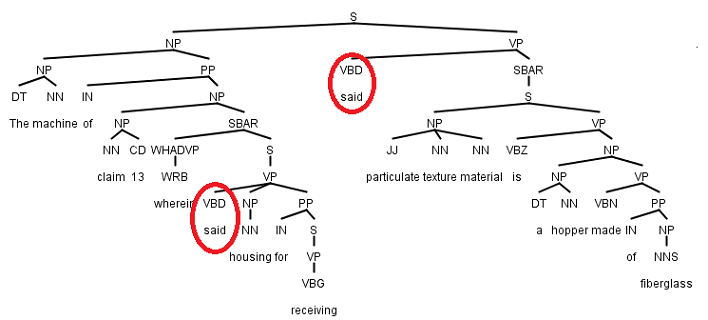
Software packages that are used to generate dependencies from sentences such as Stanford’s Dependency Software are trained typically on a corpus of written text from newspaper articles such as the Wall Street Journal. Patent claims, which must combine a mix of legal and technical terms, and must fit the entire legal scope of a part of an invention in one sentence, use grammar and language not typically found in newspaper articles. As [19] and [20] discuss and as can be observed in Fig. 2, this can adversly affect the way NLP parsers work with patent claims.
One way to fix the dependencies was discovered by noting that some words are given the wrong parts of speech tag. By forcing these incorrect parts of speech tags (initially generated by Stanford’s POS Tagger) to be correct, the dependencies can be made correct. We had noticed before that most of the problems in the parsing of the sentence came from words that the parser tagged incorrectly as verbs. By focusing on just correctly re-tagging words declared to be verbs, a much more accurate parse and set of dependencies could be developed.
An automated system that will correct parts of speech tags can be created to correct this issue but data of incorrect POS tags and correct POS tags needed to be collected first. An Amazon Mechanical Turk campaign was run to gather our data. This campaign provided workers with segments of patent claims and asked them what parts-of-speech tag each “verb” actually is. Data we deemed acceptable (given to us by those that correctly completed randomly inserted test questions) was then used as training data for our automatic correct.
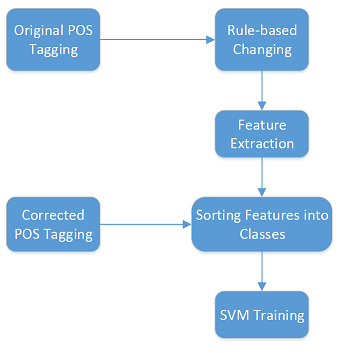
The automatic corrector for patent claims that we developed follows a training stage as shown in Fig. 3 and a testing stage as shown in Fig. 4. To perform feature extraction in this model, we gather the verb-in-question as well as both the word that immediately precedes it as well as the word that immediately follows it. We generate word vectors of these three words using word2vec in order to create a vector that not only accurately and uniformly represents the words as vectors but also allows similar sets of words to be closer than dissimilar sets of words.
We noticed when investigating this problem by hand initially that some words that were tagged as a verb are always another specific tag. For instance, the word “said” is always used as an adjective (e.g. “said motorized vehicle” where the claim is referencing the motorized vehicle that was discussed earlier) even though it is almost always declared to be a verb by the POS tagger. The rule-based corrector is just a set of ever-expanding and specific rules developed to automatically change and set the POS tags for those words that we noticed should always be a particular tag.
We have confirmed that the automatic tag corrector allows for the creation of parsed patent claims that more accurately reflect the true parse of the patent claims. Using parse trees generated from the AMT data as the gold standard, we compared the parse trees from generated straight from the Stanford Parser and the trees generated after using our automatic tag corrector. No matter how we split which portion of the data was the training data and which portion was the testing data, the parse trees generated after using our automatic corrector were closer to the AMT results than the plain Stanford Parser parse trees.
The testing stage is performed multiple times after the initial correcting. This is done because, sometimes, after rerunning the POS tagger, different words are incorrectly labeled as verbs. During each round these new verbs are rerun to determine their correct POS tags before these corrected tags (as well as the corrected tags from the previous rounds) are fed back into the system until no new verbs are obtained.
After we have gathered our data, one area of interest that we hope to use it is in the field of patent classification. Our initial experiments involved determining the best features to use in an SVM-based classification system for the USPC classification system.
We performed an initial test run of future classification experiments using just two classes: 714/748 and 714/763 of the USPC system. These two classes fall under the main class of “Error Detection/Correction and Fault Detection/Recovery”. Class 714/748 is labeled as “Request for Retransmission” which itself is a subclass to Class 714/746 (“Digital Data Error Correction”) which itself is also a subclass to Class 714/699 (“Pulse or Data Error Handling”). Class 714/763 is labeled as “Memory Access”. This class is a subclass of Class 714/752 (“Forward Correction by Block Code”) which is a subclass of Class 714/746 which is a subclass of Class 714/699.
For the experiments, we ran 5 different systems as well as combinations of those five. We generated basic tfidfs over the trigrams of both the claims (claim_tfidf) and the abstract (abstract_tfidf). We also generated dependencies over both of them (claim_origDep and abstract_dep). Finally we fixed the dependencies of the claims and rerun them to generate fixed dependencies (claim_fixDep). Classification was done using a simple SVM.
While neither of the two claim dependencies features outperformed the basic trigram features of the claims, they did provide improvement when we combined them. In addition, by fixing the dependencies, we obtain a much better performance than using the original original. As the system learns more about the text, both in physical (trigrams) and gramatical (dependencies) structure, the performance improves.
More complicated experiments in this field will be run to determine just how much improvement is possible by using different features.
Similar to the previous topic, another topic we are interested in is identifying patents related to particular standards technologies via a similar classification system. A key issue that is of increasing importance to the development of industrial technology standards such as communications standards has been potential infringement on existing patents, and the resulting necessary licensing required to implement the standard. This issue is of importance to nearly all of the players involved in the associated patent economy. Traditionally, this issue has been handled via IPR disclosure mechanisms, however, this leaves out consideration of patent holders not actively participating in the standardization process but holding patents that are infringed upon by the standard. Were standards organizations to know, at a low cost, that such patents existed, they could potentially avoid them by standardizing around them. On the other side, IP middlemen would like to know about these patents, as these form interesting patents to buy. The government would like to be able to detect this as well, as it could form a key issue when examining patents at the USPTO, as well as in reducing the burden on the Federal courts with the associated cases. Additionally, the IPR disclosure process can take a long time and standards organizations involve competing businesses, so low-cost mechanisms of tracking what competitors are filing that are essential for the standards would be desirable as well. We are designing algorithms that will detect whether or not a patent is essential for a standard. These algorithms could provide powerful tools for the monitoring and evaluation of patents for a wide variety of stakeholders.
Presently, this is a labor intensive task requiring tedious and thorough review of large documents by both legal and engineering/scientific experts, using years of training and hours of effort to register vague, arcane, or outdated language and terminology against often newly minted vocabulary buried within gigantic unwieldy documents. Determining which patents are essential for implementing parts of a standard is a key high value problem for many players in the intellectual property economy, and hence the availability of a recommender system to speed the retrieval and registration work would be widely appreciated.
In addition to gathering training and evaluation “ground-truth” data regarding these patent to standards maps to be carried out as part of data-collecting campaign, we will expend substantial effort developing information retrieval systems oriented toward mapping patent claim language to language in standards. A key component of this work will be the adaptation of NLP tools to the language found in patent claims and standards enabled through the data collected previously, which will enable us to separate the underlying meaning of claims and standards from the jargon and language patterns they must use.
Fortunately, the existing base of literature on cross document class information retrieval is expected to be useful for the patent to standard mapping task, and many of these also have integrated existing NLP tools. Most likely, the system will build off what appears to be a developing consensus in the design of patent information retrieval systems. In particular designs appear to have converged to performing query expansion [21] informed with pseudo relevance feedback [22, 23, 24], could be informed by ontologies [25, 26, 27, 28, 29], and will probably need to be informed by sources such as wikipedia [30] so as to recognize variants of the same terms. Additionally, the design may potentially generate multiple queries [31], and will likely integrate (automatically classified [32, 33, 34, 35, 36]) patent subject codes, as well as syntax structures [37] learned through NLP, in the retrieval and ranking [38].
Another key novel aspect in our approach will be the integration of online and active learning into the recommendation system to enable it to continue to learn online as trained users interact with it. When a recommended map between a patent claim and the standard is accepted and used by the patent professional using the system, this provides a new bit of training information to enable the classifiers embedded into the retrieval system to further adapt. When it is rejected and another one is entered into the system by the expert, this too provides a new bit of training information with which to adapt the classifiers. Additional to this online adaptation, active learning [39, 40] can be utilized during the initial phase of hand mapping patents with claims known to be essential to parts of a standard. The purpose of integrating active learning at this stage is to select which of these patents to map to standards with highest priority by selecting those that appear to be the most informative for further training the classifier. By integrating the training of the classifier into the labeling process and selecting the data points that are most informative to label, the amount of data that will be required to be labeled to train the classifier to a given performance will be decreased relative to a technique which labels the data blindly of the classifier.
References
[1] R. C. Faber, Landis on Mechanics of Patent Claim Drafting. Practising Law Institute, 1990.
[2] I. A. Lateef and M. R. Zoretic, “The U.S. Patent Litigation Process.” December 2010.
[3] Maura R. Grossman and Gordon V. Cormack, “Technology-Assisted Review in E-Discovery Can Be More Effective and More Efficient than Exhaustive Manual Review,” Richmond Journal of Law and Technology, vol. XVII, no. 3, 2011.
[4] D. B. Garrie and Y. M. Griver, “Unchaining E-Discovery in the Patent Courts,” Washington Journal of Law, Technology, and Arts, vol. 8, no. 4, pp. 487–500, 2013.
[5] USPTO, Manual of Patent Examining Procedure, 8th ed., August 2012.
[6] IEEE Standards Association, Understanding Patent Issues During IEEE Standards Development, 2012.
[7] IEEE-SA PatCom, Patent Slides for Standards Development Meetings, 2012.
[8] IEEE-SA PatCom, Relationship of IEEE-SA Patent Policy/LoAs to Modification of IEEE Standards by Other Standards Bodies, 2012.
[9] IEEE-SA PatCom, Slides about IEEE patent Policy, 2012.
[10] 3GPP, 3GPP Legal Matters.
[11] C. Lagrost, D. Martin, C. Dubois, and S. Quazzotti, “Intellectual property valuation: how to approach the selection of an appropriate valuation method,” Journal of Intellectual Capital, vol. 11, no. 4, pp. 481–503, 2010.
[12] R. Pitkethly, “The valuation of patents: A review of patent valuation methods with consideration of option based methods and the potential for further research,” Research Papers in Management Studies - University of Cambridge Judge Institute of Management Studies, 1997.
[13] R. A. Neifeld, “A macro-economic model providing patent based company financial indicators and automated patent valuations,” tech. rep., PantrosIP, 2005.
[14] M. T. Meeks and C. A. Eldering, “Patent valuation: Aren’t we forgetting something-making the case for claims analysis in patent valuation by proposing a patent valuation method and a patent-specific discount rate using the capm,” Nw. J. Tech. & Intell. Prop., vol. 9, no. 3, pp. 194–245, 2010.
[15] R. A. Neifeld, “Macro-economic model providing patent valuation and patent based company financial indicators, a,” Journal of the Patent and Trademark Office Society, vol. 83, pp. 211–222, March 2001.
[16] D. Drews, The Cost Approach to IP Valuation: Its Uses and Limitations. IPMetrics LLC, January 2001.
[17] V. Nastase, J. S. Shirabad, and M. F. Caropreso, “Using Dependency Relations for Text Classification,” in Canadian AI 2006 (poster), 2006.
[18] E. D’hondt, S. Verberne, C. Koster, and L. Boves, “Text Representations for Patent Classification,” Association for Computational Linguistics, vol. 39, no. 3, pp. 755–775, 2013.
[19] K. H. Atkinson, “ Toward a More Rational Patent Search Paradigm,” in PaIR ’08 Proceedings of the 1st ACM workshop on Patent information retrieval, (Napa Valley, California, USA), pp. 37–40, October 2008.
[20] S. Verberne, E. D’hondt, and N. Oostdijk, “Quantifying the Challenges in Parsing Patent Claims,” in 1st International Workshop on Advances in Patent Information Retrieval (AsPIRe10), (Milton Keynes), March 2010.
[21] D. Ganguly, J. Leveling, and G. J. F. Jones, “United we fall, Divided we stand: A Study of Query Segmentation and PRF for Patent Prior Art Search,” in 4th International Workshop on Patent Information Retrieval (PaIR’11) at CIKM, (Glasgow, Scotland), October 2011.
[22] D. Ganguly, J. Leveling, W. Magdy, and G. J. F. Jones, “Patent Query Reduction using Pseudo-Relevance Feedback,” in 20th ACM Conference on Information and Knowledge Management (CIKM 2011), (Glasgow, Scotland), October 2011.
[23] P. Mahdabi and F. Crestani, “Learning-Based Pseudo-Relevance Feedback for Patent Retrieval,” in 5th Information Retrieval Facility Conference, vol. 7356, (Vienna, Austria), pp. 1–11, July 2012.
[24] P. Mahdabi and F. Crestani, “The effect of citation analysis on query expansion for patent retrieval,” Information Retrieval, vol. 17, no. 5-6, pp. 412–429, 2014.
[25] S. Taduri, G. T. Lau, K. H. Law, H. Yu, and J. P. Kesan, “Developing an Ontology for the U.S. Patent System,” in Proceedings of the 12th Annual International Digital Government Research Conference: Digital Government Innovation in Challenging Times, (College Park, MD, USA), pp. 157–166, June 2011.
[26] S. Taduri, G. T. Lau, K. H. Law, H. Yu, and J. P. Kesan, “An Ontology-Based Interactive Tool to Search Documents in the U.S. Patent System,” in Proceedings of the 12th Annual International Digital Government Research Conference: Digital Government Innovation in Challenging Times, (College Park, MD, USA), pp. 339–330, June 2011.
[27] S. Taduri, G. T. Lau, K. H. Law, H. Yu, and J. P. Kesan, “An Ontology to Integrate Multiple Information Domains in the Patent System,” (Chicago, IL, USA), pp. 23–25, May 2011.
[28] H. Yu, S. Taduri, J. Kesan, G. Lau, and K. H. Law, “Retrieving Information Across Multiple, Related Domains Based on User Query and Feedback: Application to Patent Laws and Regulations,” in ICEGOV ’10 Proceedings of the 4th International Conference on Theory and Practice of Electronic Governance, (Beijing, China), pp. 143–151, October 2010.
[29] S. Taduri, H. Yu, G. Lau, K. Law, and J. Kesan, “Developing a Comprehensive Patent Related Information Retrieval Tool,” Journal of Theoretical and Applied Electronic Commerce Research, vol. 6, pp. 1–16, August 2011.
[30] B. Al-Shboul and S.-H. Myaeng, “Wikipedia-based query phrase expansion in patent class search,” Information Retrieval, vol. 17, no. 5-6, pp. 430–451, 2014.
[31] D. Zhou, M. Truran, J. Liu, and S. Zhang, “Using multiple query representations in patent prior-art search,” Information Retrieval, vol. 17, no. 5-6, pp. 471–491, 2014.
[32] T. Xiao, F. Cao, T. Li, G. Song, K. Zhou, J. Zhu, and H. Wang, “KNN and Re-ranking Models for English Patent Mining at NTCIR-7,” in Proceedings of NTCIR-7 Workshop Meeting, (Tokyo, Japan), pp. 333–340, December 2008.
[33] H. Nanba, T. Kondo, and T. Takezawa, “Hiroshima City University at NTCIR-8 Patent Mining Task,” in Proceedings of NTCIR-8 Workshop Meeting, (Tokyo, Japan), June 2010.
[34] D. Ji, H. yu Zhao, and D. feng Cai, “Using the Multi-level Classification Method in the Patent Mining Task at NTCIR-7,” in Proceedings of NTCIR-7 Workshop Meeting, (Tokyo, Japan), pp. 362–364, December 2008.
[35] G. Cao, J.-Y. Nie, and L. Shi, “NTCIR-7 Patent Mining Experiments at RALI,” in Proceedings of NTCIR-7 Workshop Meeting, (Tokyo, Japan), December 2008.
[36] A. Fujino and H. Isozaki, “Multi-label Classification using Logistic Regression Models for NTCIR-7 Patent Mining Task,” in Proceedings of NTCIR-7 Workshop Meeting, (Tokyo, Japan), December 2008.
[37] G. Ferraro and L. Wanner, “Towards the derivation of verbal content relations from patent claims using deep syntactic structures,” Knowledge-Based Systems, vol. 24, no. 8, pp. 1233–1244, 2011.
[38] M. Verma and V. Varma, “Patent Search using IPC Classification Vectors,” in PaIR ’11 Proceedings of the 4th workshop on Patent information retrieval, (, Glasgow, Scotland, UK), pp. 9–12, October 2011.
[39] S. Tong and D. Koller, “Support Vector Machine Active Learning with Applications to Text Classification,” Journal of Machine Learning Research, vol. 2, no. -, pp. 45–66, 2001.
[40] S. Tong, ACTIVE LEARNING: THEORY AND APPLICATIONS. PhD thesis, STANFORD UNIVERSITY, August 2001.