Vision-Based Aerial Object Detection and Classification
There has been a proliferation of Unmanned Aerial Systems (UAS) applied to multitudes of areas including agriculture, delivery, logistics, disaster relief, surveillance, etc. It can be imagined in near future, as depicted in some science fiction movies, that there will be a swarm of UASs operating in high density over well populated areas, such as in urban environments. As such, safe and reliable UAS operation is crucial for public safety. Collision of UASs over areas occupied by people is of primary concern here. There are a variety of scenarios that may result such catastrophes, including collision with a manned aircraft, other UASs, birds, other floating objects, tall buildings, powerlines, natural landscape, etc. Therefore, a UAS has to be able to accurately and timely detect these objects such that the onboard navigation and control system can fly the UAS to avoid any potential collision. For a drone to be able to fly safely, it must perceive nearby objects, both dynamic and stationary, and estimate their future states to avoid collisions in its flight path. These state estimates are then fed to the onboard navigation and control system for safe flight trajectory computation. Our research here is to estimate limits and failures of computer vision, of both current and future systems, so that appropriate FAA guidelines can be established for successful UAS operations over populated areas. Specifically we review relevant computer vision related publications, and also develop in-house vision algorithms to accurately estimate current and future UAS computer vision performance limitations.

We’ve also introduced two versions of a dataset for long-distance UAV detection called the Long-Range Drone Detection Dataset (LRDD), and we are actively expanding it with the goal of creating one of the largest and most diverse drone detection datasets in the world [1][2]. You can access it from here.
Enhancing Long-Range UAV Detection
As small drones become increasingly prevalent in both commercial and security applications, accurately detecting them at long range poses a critical challenge due to their minimal pixel footprint in high-resolution images. Our research addresses this challenge by integrating the Slicing Aided Hyper Inference (SAHI) [3] framework with YOLOv8. This method divides large images into overlapping patches, preserving detail and significantly improving detection accuracy, especially for small, distant UAVs. Extensive evaluations on both real-world and synthetic datasets [4] show that our approach yields substantial performance gains over baseline models, offering a promising solution for drone surveillance and critical infrastructure monitoring.

Context-Aware Recognition: Enabling Open-World Object Detection Through Scene Understanding

Our research focuses on empowering visual recognition systems with contextual scene understanding to identify previously unseen objects—moving beyond fixed-category detection. At the core of this effort is ADAM, a training-free framework that mimics human-like inference by using Large Language Models (LLMs) to generate semantic labels for unknown objects based on the context of known elements in a scene. By building a self-refining repository of visual embeddings and context-driven labels, ADAM enables open-world object detection without retraining. This broader goal of inferring object presence through context also guides our related work, where we enhance conventional detectors by leveraging LLMs to recover missed objects in visually degraded conditions, such as occlusion or low visibility.
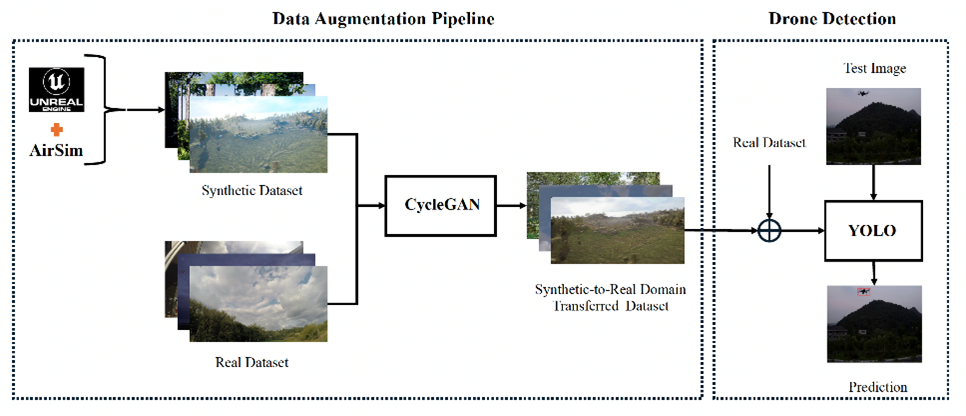
Bridging the Synthetic-to-Real Domain Gap
In real-world computer vision applications, collecting and labeling large-scale, diverse datasets is often impractical. To overcome this, we use synthetic data generation with Unreal Engine and AirSim to create rich, controllable environments for training. These simulated datasets allow for scalable and efficient data creation under varied conditions.
However, models trained purely on synthetic data often struggle when deployed in the real world due to the domain gap between simulated and real imagery. To address this, our research focuses on strategies that improve generalization from synthetic to real domains. By reducing the impact of domain shift, we aim to make vision models more robust and reliable in real-world settings.

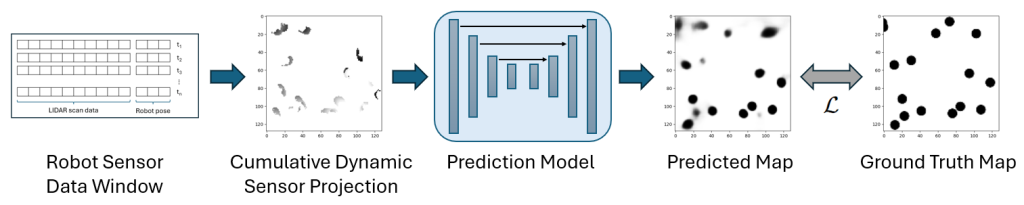
Scene State Modeling
Automated mobile systems such as robots and drones need to keep accurate models of the state of their surroundings, including features such as object locations, distances, and motion, in order to avoid collisions and to navigate effectively. To effectively accomplish this, we are developing methods to improve Monocular Depth Estimation (the prediction of pixel distances from single camera images) through the use of synthetic data creation, as well as the prediction of object movement through dynamic map states using computer vision techniques to process LIDAR sensor data.

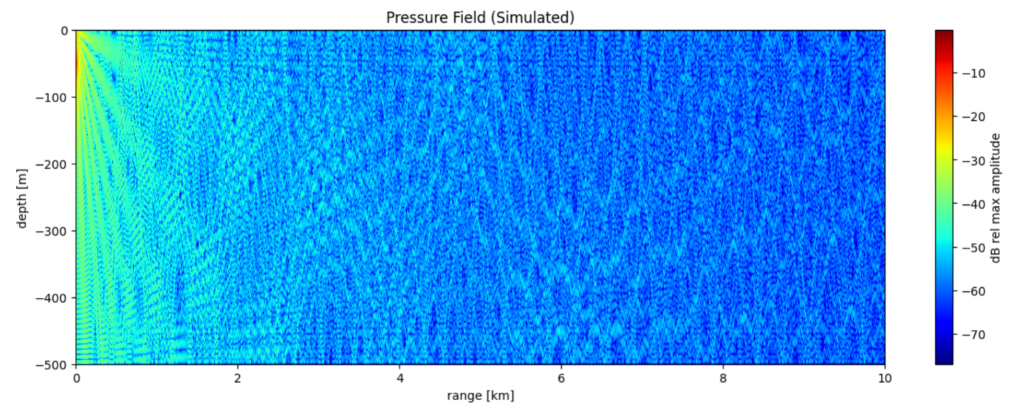
Acoustic Scene Understanding
Accurately classifying, detecting, and localizing acoustic sources is essential for both underwater and airborne applications, including naval operations, environmental monitoring, autonomous navigation, robotics, and surveillance. These tasks are challenging due to the complex and dynamic nature of acoustic environments—ranging from high ambient noise and fluctuating propagation in water to multipath interference and reverberation in air.
Traditional methods such as Matched Field Processing (MFP) in underwater acoustics or beamforming in air acoustics often rely on accurate environmental models and sensor calibration, which may be unavailable or unreliable in real-world conditions. To address these limitations, our lab focuses on data-driven approaches that leverage deep learning to learn spatial and temporal patterns directly from raw microphone or hydrophone recordings. Models such as convolutional neural networks (CNNs), deep neural networks (DNNs), and attention-based Transformers are employed to perform tasks such as sound source classification [6], direction-of-arrival (DOA) estimation [7], and range estimation [8] without requiring precise environmental priors.
We explore a wide range of feature representations, including mel-spectrograms, Generalized Cross-Correlation with Phase Transform (GCC-PHAT), and raw time-series signals, processed using techniques such as the Short-Time Fourier Transform (STFT) and Fast Fourier Transform (FFT). These are tailored for both underwater and airborne applications to ensure robustness across domains. We also develop custom algorithms designed to handle the unique propagation characteristics of each medium.
Given the scarcity of labelled real-world data, we also invest significant effort in studying acoustic environments and propagation models and using this knowledge to generate labeled data using tools based on Normal Mode Theory, Ray-Tracing methods, and other physical modelling approaches. Our objective is to bridge the gap between simulated and real-world data, enabling robust training of deep learning models that generalize well to operational conditions.
References
[1] A. Rouhi, H. Umare, S. Patal, R. Kapoor, N. Deshpande, S. Arezoomandan, P. Shah, and D. Han, “Long-range drone detection dataset,” in 2024 IEEE International Conference on Consumer Electronics (ICCE). IEEE, 2024, pp. 1–6.
[2] A. Rouhi, S. Patel, N. McCarthy, S. Khan, H. Khorsand, K. Lefkowitz, and D. Han. “LRDDv2: Enhanced Long-Range Drone Detection Dataset with Range Information and Comprehensive Real-World Challenges,” in 2024 International Symposium of Robotics Research (ISRR). IEEE, 2024, pp. 1-6.
[3] F. C. Akyon, S. O. Altinuc, and A. Temizel, “Slicing aided hyper inference and fine-tuning for small object detection,” in 2022 IEEE International Conference on Image Processing (ICIP). IEEE, 2022, pp. 966–970.
[4] H. Khorsand, S. Arezoomandan and D. K. Han, “Enhanced Long-Range UAV Detection: Leveraging Slicing Aided Hyper Inference with YOLOv8,” 2025 IEEE International Conference on Consumer Electronics (ICCE), Las Vegas, NV, USA, 2025, pp. 1-6, doi: 10.1109/ICCE63647.2025.10930186.
[5] Arezoomandan, S., Klohoker, J., Han, D.K. (2025). Data Augmentation Pipeline for Enhanced UAV Surveillance. In: Antonacopoulos, A., Chaudhuri, S., Chellappa, R., Liu, CL., Bhattacharya, S., Pal, U. (eds) Pattern Recognition. ICPR 2024. Lecture Notes in Computer Science, vol 15306. Springer, Cham. https://doi.org/10.1007/978-3-031-78172-8_24
[6] Q. T. Vo and D. K. Han, “Underwater acoustic signal classification using hierarchical audio transformer with noisy input,” in 2023 IEEE 33rd International Workshop on Machine Learning for Signal Processing (MLSP), pp. 1–6, 2023.
[7] Q. T. Vo and D. K. Han, “Resnet-conformer network with shared weights and attention mechanism for sound event localization, detection, and distance estimation,” in 2024 DCASE2024 Challenge, Tech. Rep., 2024.
[8] Q. T. Vo, J. Woods, P. Chowdhury, and D. K. Han,”Adaptive Control Attention Network for Underwater Acoustic Localization and Domain Adaptation,” in 2025 33rd European Signal Processing Conference (EUSIPCO), pp. 1-6, 2025.