The effect of chemical environment and temperature on the domain structure of free-standing \(BaTiO_3\) via in-situ STEM#
Keywords#
BaTiO3 free-standing film, chemical environment, in-situ heating TEM, domains.
Abstract#
Ferroelectrics, due to their polar nature and reversible switching, can be used to dynamically control surface chemistry for catalysis, chemical switching, and other applications such as water splitting. However, this is a complex phenomenon where ferroelectric domains orientation and switching are intimately linked to surface charges. In this work, we study the temperature-induced domain behavior of ferroelectric-ferroelastic domains in free-standing BaTiO3 films under different gas environments,including reducing and oxidizing by in-situ scanning transmission electron microscopy(STEM). We also establish an automated pathway to statistically disentangle and detect domain structure transformations using deep autoencoders, providing a pathway towards real-time analysis. Our results show a clear difference in the temperature at which phase transition occur and domain behaviour between the environments, with a peculiar domain reconfiguration at low temperatures, from a-c to a-a at ~60°C. The reducing environment exhibits a rich domain structure, while under the oxidizing environment, the domain structure is largely suppressed. The direct visualization provided by in-situ gas and heating STEM is a novel technique that allows the study that external variables such as gas, pressure, and temperature have on oxide surfaces in a dynamic manner, which is of particular interest for further understanding surface-screening mechanisms in ferroelectrics.
Imports#
# For the notebook to work you must have m3_learning installed
# !pip install m3-learning
import sys
import matplotlib.pyplot as plt
import warnings
import torch
# warnings.filterwarnings("ignore")
# # if you want to modify files,
# # edit this to match the location whwere you downloaded the m3_learning package
# m3_package_location = '/home/xinqiao/'
# sys.path.append(f"{m3_package_location}/m3_learning/m3_learning/src")
%load_ext autoreload
%autoreload 2
from m3_learning.viz.printing import printer
from m3_learning.viz.style import set_style
from m3_learning.viz.Movies import make_movie
from m3_learning.nn.Bright_Field_NN.Dataset import Bright_Field_Dataset
from m3_learning.nn.Bright_Field_NN.Viz import Viz
from m3_learning.nn.Bright_Field_NN.Autoencoder import ConvAutoencoder
from m3_learning.viz.layout import layout_fig, labelfigs
from m3_learning.util.file_IO import download_and_unzip
# Specify the `save_path`` where you saved your data
# modify `save_path` and `fig_path` to fit your own file system
save_path = './../../../Data/2023_Bright_Field'
fig_path = save_path.replace("Data", "Figures") + '/'
2023-11-14 12:38:03.311087: I tensorflow/tsl/cuda/cudart_stub.cc:28] Could not find cuda drivers on your machine, GPU will not be used.
2023-11-14 12:38:03.344840: E tensorflow/compiler/xla/stream_executor/cuda/cuda_dnn.cc:9342] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2023-11-14 12:38:03.344873: E tensorflow/compiler/xla/stream_executor/cuda/cuda_fft.cc:609] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2023-11-14 12:38:03.344906: E tensorflow/compiler/xla/stream_executor/cuda/cuda_blas.cc:1518] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
2023-11-14 12:38:03.352840: I tensorflow/core/platform/cpu_feature_guard.cc:182] This TensorFlow binary is optimized to use available CPU instructions in performance-critical operations.
To enable the following instructions: AVX2 AVX512F FMA, in other operations, rebuild TensorFlow with the appropriate compiler flags.
2023-11-14 12:38:04.037910: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
Loading Data from Zenodo#
# # list of files to download from zenodo
# # uncomment this if you need to download the files from zenodo
# files = [ r'Annealed.zip',
# r'Nitrogen.zip',
# r'Oxygen.zip',
# r'Vacuum.zip',
# r'Annealed_epoch%2000043_trainloss%200.2921_coef%205.0000E-08.pkl',
# r'Nitrogen_epoch_00060_trainloss_0.2925_coef_9.0000E-08.pkl',
# r'Oxygen_epoch_00037_trainloss_0.3050_coef_5.0000E-08.pkl',
# r'Vacuum_epoch_00137_trainloss_0.3150_coef_3.0250E-07.pkl'
# ]
# # downloads all the files
# for file in files:
# # Download the data file from Zenodo
# url = f"https://zenodo.org/record/10092383/files/{file}?download=1"
# # download the file
# download_and_unzip(file, url, save_path)
Setting up Dataset#
Note:
Make sure your data is saved in the format
"*/{some folder name}/{Ramp_Up or Ramp_Down}/{temperature}.png". This will ensure the images are read into the h5 file in the correct order.The resulting h5 file will be saved in the same folder of the
"{some folder name}"
Create dataset object#
This dataset will contain your cropped images and windows
# defines Dataset object using images from specified folder
dset = Bright_Field_Dataset(datapath = f'{save_path}/Annealed',
combined_name = 'Annealed',
verbose=False)
# list paths of image data in order
dset.get_temp_paths()[:5]
['./../../../Data/2023_Bright_Field/Annealed/Ramp_Up/23.png',
'./../../../Data/2023_Bright_Field/Annealed/Ramp_Up/30.png',
'./../../../Data/2023_Bright_Field/Annealed/Ramp_Up/40.png',
'./../../../Data/2023_Bright_Field/Annealed/Ramp_Up/50.png',
'./../../../Data/2023_Bright_Field/Annealed/Ramp_Up/60.png']
# Look at a raw image using the state/temperature
im = dset.get_raw_img(state = 'Ramp_Up',
temperature = 23)
plt.imshow(im)
plt.show()
# Look at a raw image using index
im = dset.get_raw_img(path_index=0)
plt.imshow(im)
plt.show()
Creating Visualization object#
This contains tools for visualizing raw data and training results. It also lahys out figures
# builds the printer object
printing = printer(basepath=fig_path,fileformats=['png','svg'])
# Set the style of the plots
set_style("printing")
printing set for seaborn
# builds the printer object
printing = printer(basepath=fig_path,fileformats=['png','svg'],verbose=False)
# Set the style of the plots
set_style("printing")
# create vizualizer object
viz = Viz(dset,printer=printing)
# add scalebar
# Note that this should be the scalebar for the raw images
viz.scalebar_ = {"units": "nm", # choose units
"width": 273.4, # width of the raw image
"scale length": 50 # width you want for the colorbar
}
printing set for seaborn
# view raw image. You can use
img_name = ['Ramp_Up','23']
viz.view_raw(img_name)
Preprocessing#
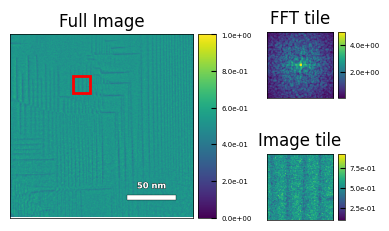
Images were cropped, and Gaussian background subtraction was applied. This result is written to the dataset named ‘All_filtered’ in the h5 file.
The Pycroscopy package was used to sample (128,128) sized sliding windows and apply a Hanning window and Fast Fourier Transform (FFT). Applying FFT to windowed images provides localized information about periodicity and reduces bias caused by sample warping. In standard TEM, the FFT is used to calculate things such as lattice (d) spacing and planar orientation.
The logarithm is applied, along with a threshold and standard scaling.
The preprocessed data is a stack of (128,128) windows of length \(T•n•n\), where \(T\) is the number of temperatures sampled and \(n\) is the number of windows sampled along each side of the image.
# Write image data to h5 file (DO ONE TIME)
# saves original images as well as
# cropped images with gaussian filter applied
# Make sure your cropped image size is divisible by the windowing step
dset.write_h5(200,300,1400)
Show code cell output
0%| | 0/43 [00:00<?, ?it/s]
2%|▏ | 1/43 [00:00<00:18, 2.28it/s]
5%|▍ | 2/43 [00:00<00:17, 2.34it/s]
7%|▋ | 3/43 [00:01<00:16, 2.37it/s]
9%|▉ | 4/43 [00:01<00:16, 2.38it/s]
12%|█▏ | 5/43 [00:02<00:16, 2.33it/s]
14%|█▍ | 6/43 [00:02<00:15, 2.36it/s]
16%|█▋ | 7/43 [00:02<00:15, 2.38it/s]
19%|█▊ | 8/43 [00:03<00:14, 2.40it/s]
21%|██ | 9/43 [00:03<00:14, 2.40it/s]
23%|██▎ | 10/43 [00:04<00:13, 2.36it/s]
26%|██▌ | 11/43 [00:04<00:13, 2.33it/s]
28%|██▊ | 12/43 [00:05<00:13, 2.35it/s]
30%|███ | 13/43 [00:05<00:12, 2.37it/s]
33%|███▎ | 14/43 [00:05<00:12, 2.32it/s]
35%|███▍ | 15/43 [00:06<00:11, 2.33it/s]
37%|███▋ | 16/43 [00:06<00:12, 2.19it/s]
40%|███▉ | 17/43 [00:07<00:11, 2.24it/s]
42%|████▏ | 18/43 [00:07<00:11, 2.24it/s]
44%|████▍ | 19/43 [00:08<00:11, 2.18it/s]
47%|████▋ | 20/43 [00:08<00:10, 2.24it/s]
49%|████▉ | 21/43 [00:09<00:09, 2.28it/s]
51%|█████ | 22/43 [00:09<00:09, 2.32it/s]
53%|█████▎ | 23/43 [00:09<00:08, 2.34it/s]
56%|█████▌ | 24/43 [00:10<00:08, 2.36it/s]
58%|█████▊ | 25/43 [00:10<00:07, 2.37it/s]
60%|██████ | 26/43 [00:11<00:07, 2.37it/s]
63%|██████▎ | 27/43 [00:11<00:06, 2.37it/s]
65%|██████▌ | 28/43 [00:12<00:06, 2.36it/s]
67%|██████▋ | 29/43 [00:12<00:06, 2.27it/s]
70%|██████▉ | 30/43 [00:12<00:05, 2.30it/s]
72%|███████▏ | 31/43 [00:13<00:05, 2.31it/s]
74%|███████▍ | 32/43 [00:13<00:05, 2.14it/s]
77%|███████▋ | 33/43 [00:14<00:04, 2.17it/s]
79%|███████▉ | 34/43 [00:14<00:04, 2.23it/s]
81%|████████▏ | 35/43 [00:15<00:03, 2.27it/s]
84%|████████▎ | 36/43 [00:15<00:03, 2.31it/s]
86%|████████▌ | 37/43 [00:16<00:02, 2.33it/s]
88%|████████▊ | 38/43 [00:16<00:02, 2.35it/s]
91%|█████████ | 39/43 [00:16<00:01, 2.36it/s]
93%|█████████▎| 40/43 [00:17<00:01, 2.30it/s]
95%|█████████▌| 41/43 [00:17<00:00, 2.32it/s]
98%|█████████▊| 42/43 [00:18<00:00, 2.35it/s]
100%|██████████| 43/43 [00:18<00:00, 2.34it/s]
100%|██████████| 43/43 [00:18<00:00, 2.31it/s]
# Customize window parameters
# This will run very slow for small step sizes
window_parameters = {'fft_mode': 'abs',
'mode': 'fft',
'window_size_x': 128,
'window_size_y': 128,
'window_step_x': 32,
'window_step_y': 32,
'zoom_factor': 2,
'interpol_factor': 2.3,
'filter': 'hamming'}
# Write windows
wins = dset.write_windows(window_parms=window_parameters,
overwrite=True,
windows_group='old_windows',
filter_threshold=5)
Show code cell output
100%|██████████| 43/43 [07:19<00:00, 10.23s/it]
# You can also look at the dataset file this way, if you want to open it in the notebook.
# but you are more likely to corrupt the file
h = dset.open_combined_h5()
print(h.keys())
# Be sure to close the file after use
h.close()
h
<KeysViewHDF5 ['All', 'All_filtered', 'old_windows']>
<Closed HDF5 file>
# Get information on the h5 combined file
k = dset.get_combined_h5_info()
<HDF5 group "/" (3 members)>
<HDF5 dataset "All": shape (43, 1400, 1400), type "<f4">
<HDF5 dataset "All_filtered": shape (43, 1400, 1400), type "<f4">
<HDF5 group "/old_windows" (3 members)>
<HDF5 group "/old_windows/filler" (1 members)>
<HDF5 group "/old_windows/filler/windows" (6 members)>
<HDF5 dataset "WindowX": shape (147,), type "<f8">
<HDF5 dataset "WindowY": shape (147,), type "<f8">
<HDF5 dataset "a": shape (41,), type "<f8">
<HDF5 dataset "b": shape (41,), type "<f8">
<HDF5 group "/old_windows/filler/windows/metadata" (0 members)>
<HDF5 dataset "windows": shape (41, 41, 147, 147), type "<f4">
<HDF5 dataset "windows_data": shape (72283, 147, 147), type "<f4">
<HDF5 dataset "windows_logdata": shape (72283, 128, 128), type "<f4">
# view windows
img_name = ['Ramp_Up','23']
viz.view_window(img_name,15,10,
'/old_windows/windows_logdata')
Training#
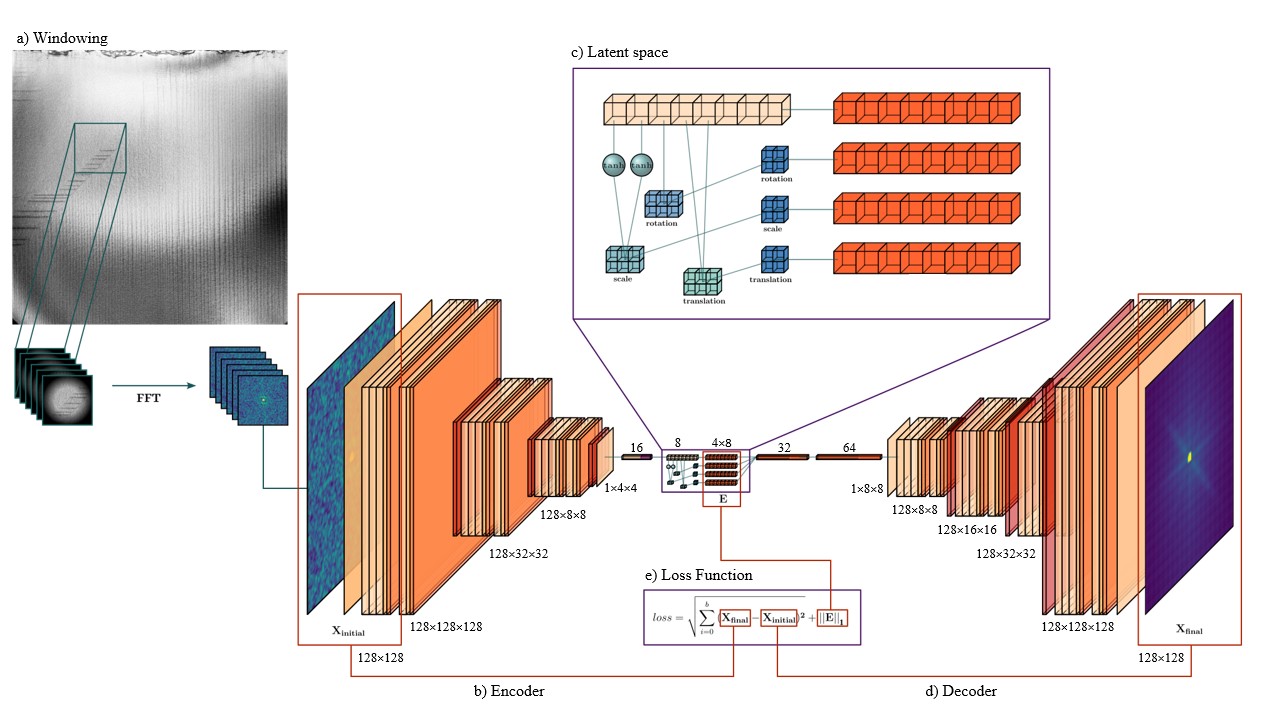
Next, the FFT dataset runs through a model inspired by the joint rotationally-invariant variational autoencoder, where input is compressed into a latent space with an additional discrete rotation representation, then reconstructed to compare to the original image. The model used in this article disentangles the input datasets scaling, rotational, and translational elements and appends them to the latent representation.
The encoder receives a batch of (128,128) images, which are downsampled and flattened to a feature vector with 8 points, as shown in Figure 2b.
The feature vector is then used to construct three affine matrices, with the first two points corresponding to the x and y scaling, the third point to the rotation angle, and the fourth and fifth points to the x and y translation. The eight features and selected affine transformations are shown in SI video.
The scaling, rotation, and translation matrices were then used to generate three respective affine grids with shape (2,2,2), and the final latent representation concatenates the feature vector and affine grids.
Finally, the feature vector and spatial transformer grids are flattened and used to reconstruct the original input.
The model parameters are tuned during training using the loss function shown in Figure2e. The Mean-Squared-Error(MSE) between the input and reconstructed images tests the latent representation for completeness, while L1 Regularization encourages sparsity and prevents overfitting.
Tips:
embedding_sizeshould be \(2n^2\). This generates an affine grid is of shape \((b,1,n,n)\) in the latent space. (ex.embedding_sizecan be \(2*2*2 = 8\) or \(2*3*3 = 18\))Don’t make \(n\) too big. The final output will be of shape \((b,4,2*n*n)\) because we stack the affine grids for decoding
If nothing saved, it is because your model is not improving. The model only saves if the loss is less than the last best loss
# defined model parameters
encoder_step_size = (128,128)
# [dset.get_shape('old_windows/windows_logdata')[-2],
# dset.get_shape('old_windows/windows_logdata')[-1]]
pooling_list = [4,4,2]
decoder_step_size = [8,8]
upsampling_list = [2,2,4]
embedding_size = 8
conv_size = 128
batch_size = 32
# set device to load model
device = "cpu"
if torch.cuda.is_available():
device = "cuda:0"
# define model
model = ConvAutoencoder(
dset=dset,
encoder_step_size=encoder_step_size,
pooling_list=pooling_list,
decoder_step_size=decoder_step_size,
upsampling_list=upsampling_list,
embedding_size=embedding_size,
conv_size=conv_size,
device=device,
learning_rate=3e-5,
)
# Load pretrained model weights if you have them
model.load_weights(
'/home/xinqiao/m3_learning/m3_learning/papers/2023_the_effect_of_chemical_environment_and_temperature_on_the_domain_structure_of_freestanding_BaTiO3_via_in_situ_STEM/Domain_Weights/(2022-05-18, 10 08)_epoch 00043_trainloss 0.2921_coef 5.0000E-08.pkl'
)
# train model
h = dset.open_combined_h5()
model.Train(
dataset_key = '/old_windows/windows_logdata',
coef_1=0,
coef_2=0,
epochs=1,
with_scheduler=False,
folder_path=f"Domain_Weights_{dset.combined_name}",
batch_size=batch_size,
save_all=True
)
h.close()
Show code cell output
100%|██████████| 2259/2259 [11:38<00:00, 3.23it/s]
Epoch: 000/000 | Train Loss: 6.7417e-01
.............................
Analyze embeddings#
# Load pretrained model weights if you have them
model.load_weights(
'/home/xinqiao/m3_learning/m3_learning/papers/2023_the_effect_of_chemical_environment_and_temperature_on_the_domain_structure_of_freestanding_BaTiO3_via_in_situ_STEM/Domain_Weights/(2022-05-18, 10 08)_epoch 00043_trainloss 0.2921_coef 5.0000E-08.pkl'
)
# calculates embeddings for all samples windows
embedding, rotation, translation, scaling = \
model.get_embedding('/old_windows/windows_logdata')
Show code cell output
100%|██████████| 2259/2259 [06:26<00:00, 5.84it/s]
# saves embeddings to an h5 file
model.save_embedding('Annealed_embeddings',embedding, rotation, translation, scaling,
overwrite=True)
# Layout images of filtered image, embeddings, and transforms at all temperatures and saves to folder
viz.layout_embedding_affine(embedding,rotation,translation,scaling,
save_folder='embedding_affine_maps_1');
Show code cell output
100%|██████████| 43/43 [03:01<00:00, 4.21s/it]
# Builds a Movie
folder = f"./embedding_affine_maps"
output_folder = "./embedding_movies/"
# function to make the movie
make_movie("embeddings_through_temperatures",
folder, output_folder,
"png", 3, reverse=False)
Get relative areas#
# If you don't want uncertanties, don't include `err_std`
mask = viz.make_mask(embedding,t=4,c=0,
dataset_key='/old_windows/windows_logdata',
save_folder='masking',eps=1)
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[20], line 2
1 # If you don't want uncertanties, don't include `err_std`
----> 2 mask = viz.make_mask(embedding,t=4,c=0,
3 dataset_key='/old_windows/windows_logdata',
4 save_folder='masking',eps=1)
NameError: name 'embedding' is not defined
# if you include err_std, it will return three binary masks: original, lower bound, upper bound
mask,mask0,mask1 = viz.make_mask(embedding,t=4,c=0,
dataset_key='/old_windows/windows_logdata',
save_folder='masking',
eps=1,err_std=0.5)
<Figure size 640x480 with 0 Axes>
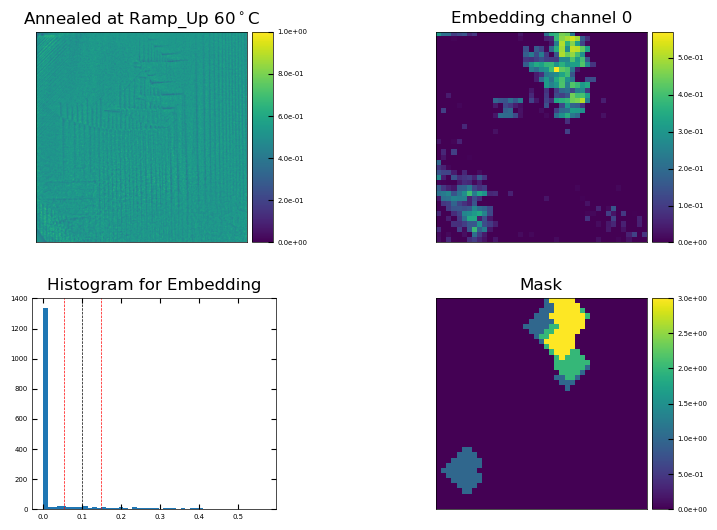
Find relative areas#
# Look at the movie generated in previous section; figure out which channels match domain patterns
channels = [0,4,6,7]
# Look at which channels are opposite of selected channels. These will be subtracted during cleaning
div_channels = [2,6,0,0]
# label the domain of each channel as keys and slope as value
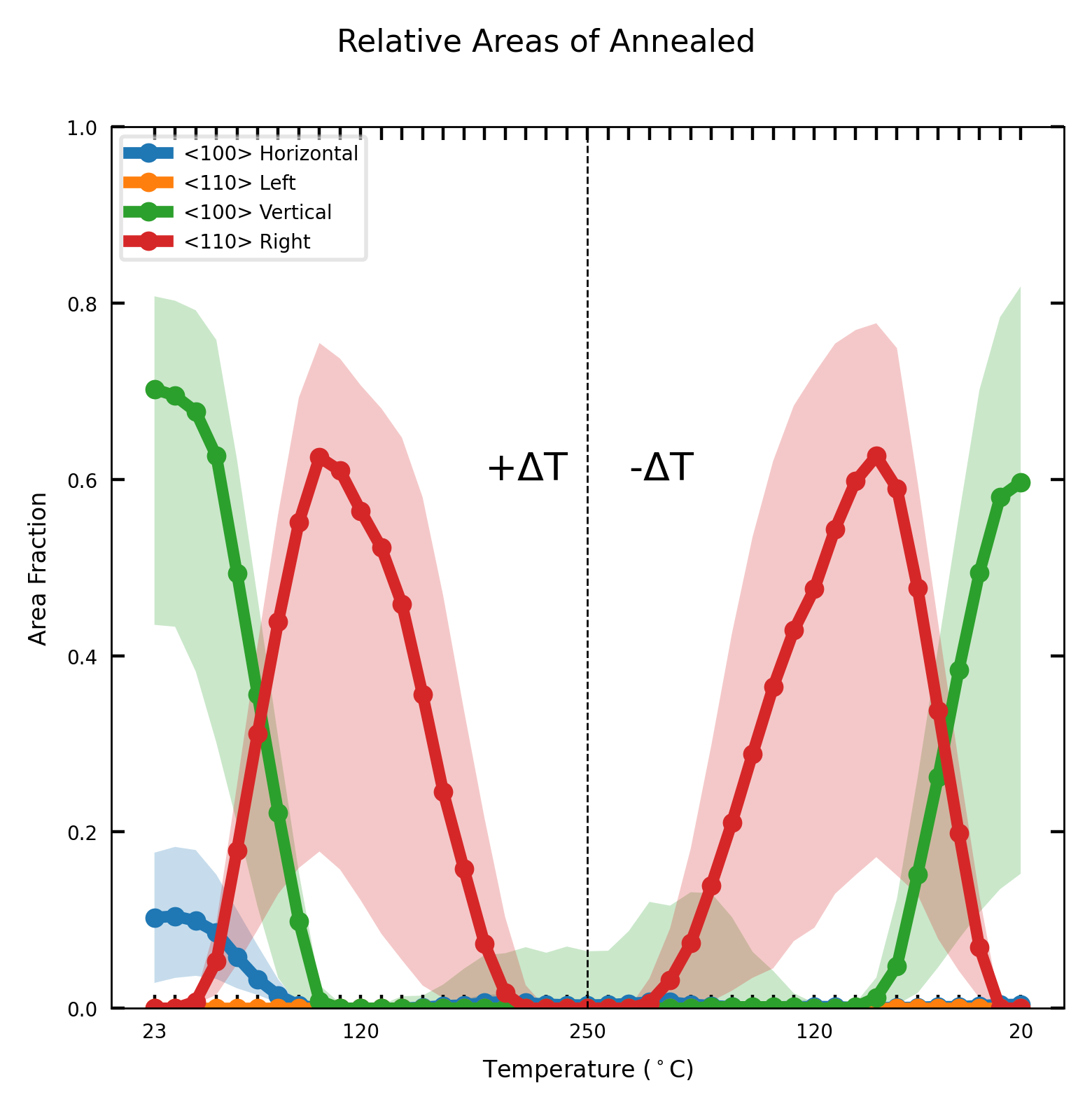
legends_dict = {'<100> Horizontal':0,
'<110> Left':45,
'<100> Vertical':90,
'<110> Right':-45}
# List format for labels
legends = list(legends_dict.keys())
# If masked=True, relative areas are calculated from only the mask
# If masked = False, we will multiply the ma
rel_areas = viz.graph_relative_area(embedding,
dataset_key='/old_windows/windows_logdata',
channels=channels,smoothing=5,
clean_div=div_channels,
legends=legends,
masked=True,
err_std=1,
save_folder=f'./Relative Areas/')
100%|██████████| 43/43 [00:00<00:00, 62.32it/s]
<Figure size 640x480 with 0 Axes>